
Ich transkribiere seit 8 Monaten jedes einzelne Meeting. Nicht die wichtigsten. Nicht 50 Prozent. Alle.
Jede Transkription wird in einem automatisierten Prozess mit Metadaten angereichert, zusammengefasst und in eine Vektordatenbank mit angeschlossenem Wissensgraphen geschoben. Meine KI-Plattform ist mit diesem Graphen verbunden.
Meetings sind dabei nur der Anfang – ein besonders wirkungsvoller Einstiegspunkt, weil in Gesprächen das meiste implizite Wissen entsteht. Doch derselbe Ansatz lässt sich auf praktisch jede Wissensquelle anwenden: Verträge und Angebote, interne Dokumentationen und Wikis, E-Mail-Korrespondenz, Support-Tickets, Projektberichte oder auch regulatorische Dokumente wie SOPs und Audit-Protokolle. Überall dort, wo Wissen heute fragmentiert in Silos liegt, kann ein Wissensgraph Zusammenhänge sichtbar machen, die sonst verloren gehen.
Das Ergebnis: Antworten in Sekunden
Ich stelle eine Frage und bekomme Antworten aus 8 Monaten Gesprächen. Präzise. Mit Kontext und Nuancen. Ohne Halluzinationen.
| Zeit | Programmpunkt |
|---|---|
| 08:00 | Begrüssung & Eröffnung |
| Vormittag | Grundlagen & Praxisberichte – Machine Learning, Deep Learning, Generative KI, Prompt Engineering + Praxisberichte |
| 12:00–13:00 | Mittagspause |
| Nachmittag | Interaktive Workshop-Stationen (max. 3–4 Teilnehmer pro Station) |
| Anschliessend | Networking |
- Speicherort der Trainingsdaten – Wo werden die Daten physisch gespeichert? Anforderung: Schweizer Rechenzentrum.
- Nutzungsrechte bei Fine-Tuning – Wem gehören die trainierten Modelle und Gewichte?
- Exportierbarkeit bei Vertragskündigung – Wie werden Daten und Modelle bei einem Exit vollständig übergeben?
| Aufgabe | Status |
|---|---|
| Finales Slide-Deck | Erledigt |
| Teilnehmerliste inkl. Dietary Restrictions | Erledigt |
| Budget-Freigabe Catering | Offen |
| Raumplan mit AV-Setup | Offen |
Antworten in Sekunden. Aus echtem Wissen. Nicht aus Vermutungen.
Was ist ein Wissensgraph – und warum ist er wichtig?
Der Kern hinter diesem System ist ein Wissensgraph. Kein Buzzword – eine Datenstruktur.
Knoten
Dinge der realen Welt: Personen, Unternehmen, Themen, Entscheidungen, Projekte.
Kanten
Beziehungen zwischen Dingen: «arbeitet bei», «hat entschieden», «widerspricht».
Ontologie
Ein Regelwerk, das definiert, wie diese Dinge zueinander stehen und welche Beziehungstypen gültig sind.
Der Unterschied zu einer normalen Datenbank: Ein Wissensgraph versteht nicht nur, dass zwei Dinge verbunden sind. Er versteht wie und warum. Das macht ihn zur idealen Grundlage für KI-Systeme, die nicht nur suchen, sondern schlussfolgern.
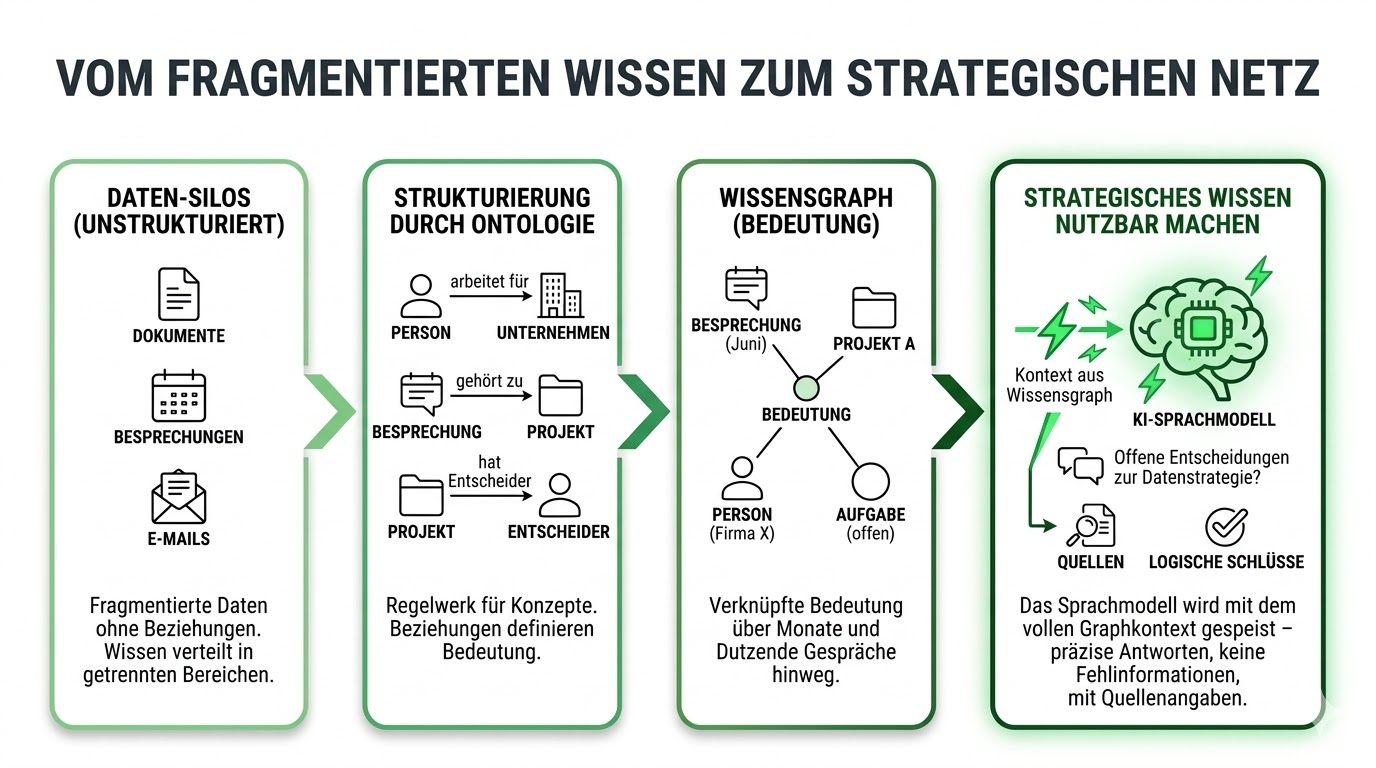
Das Problem: Berge von unstrukturiertem Wissen
Die meisten Unternehmen sitzen auf Bergen von unstrukturiertem Wissen. Meetings, E-Mails, Dokumente, Slack-Nachrichten. Alles da. Nichts verbunden. Kein System, das Bedeutung herstellt.
| Klassischer Ansatz | Wissensgraph-Ansatz |
|---|---|
| Daten in Silos (E-Mail, Docs, Chat) | Alle Quellen verknüpft in einem Graphen |
| Suche nach Keywords | Semantische Abfrage nach Bedeutung |
| Kontext geht verloren | Beziehungen bleiben erhalten |
| KI halluziniert bei fehlenden Daten | KI schlussfolgert aus echtem Wissen |
| Informationen veralten unbemerkt | Zeitliche Dimension ist eingebaut |
Rohe Modell-Intelligenz löst das nicht. GPT-5, Opus 4 oder Gemini 3 werden es nicht lösen. Denn das Modell ist nicht der Differentiator – Ihre Daten und deren Verknüpfung sind es.
Was den Unterschied macht
Was Unternehmen wirklich voranbringt, sind nicht grössere Modelle. Es sind drei Dinge:
Struktur
Daten brauchen ein Schema, eine Ordnung. Ohne Struktur bleibt alles fragmentiert – egal wie intelligent das Modell ist.
Kontext
Wer hat was wann gesagt? In welchem Zusammenhang? Kontext macht aus Daten Information und aus Information Wissen.
Beziehungen
Die Verbindungen zwischen Informationen sind oft wertvoller als die Informationen selbst. Beziehungen ermöglichen Schlussfolgerungen.
In einer Welt, in der Intelligenz zum Commodity wird, ist Bedeutung die knappste Ressource. Wer sie strukturiert, gewinnt.
Den Loop schliessen: Vom Graphen zum Sprachmodell
Damit ist jedoch erst die halbe Strecke zurückgelegt. Transkription, Anreicherung und Speicherung im Wissensgraphen bilden das Fundament – doch um den Loop zu schliessen, muss dieses strukturierte Wissen dem Sprachmodell der Wahl zugänglich gemacht werden. Als offizieller Partner von Langdock verbinden wir DSGVO-konforme, in der EU gehostete Modelle über MV-insights direkt mit dem Wissensgraphen. Damit schliesst sich der Kreis: Mitarbeitende können ihr Unternehmenswissen effektiv und präzise abfragen – und erhalten konkrete, korrekte Antworten ohne Halluzinationen.
Die technische Architektur dahinter
Für die Umsetzung verwende ich eine datenschutzkonforme Infrastruktur, die vollständig auf Schweizer respektive europäischen Servern läuft:
- Transkription & Zusammenfassung: Automatisierte Echtzeit-Transkription und Zusammenfassung der Meetings mit dem DSGVO-konformen Tool Sally.io
- Metadaten-Anreicherung & Automation: Workflow-Automation mit n8n
- Vektordatenbank: Semantische Suche über alle transkribierten Inhalte
- Wissensgraph: Verknüpfung aller Entitäten mit typisierten Beziehungen
- KI-Plattform: DSGVO-konformes Sprachmodell mit direktem Zugriff auf den Graphkontext via Langdock
Das gesamte Setup ist datenschutzkonform nach Schweizer DSG und lässt sich auch On-Premise betreiben – ein entscheidender Faktor für regulierte Branchen.
Neugierig, wie das konkret aussieht?
Erfahren Sie, wie sich ein Wissensgraph-System datenschutzkonform für Ihr Unternehmen realisieren lässt.