
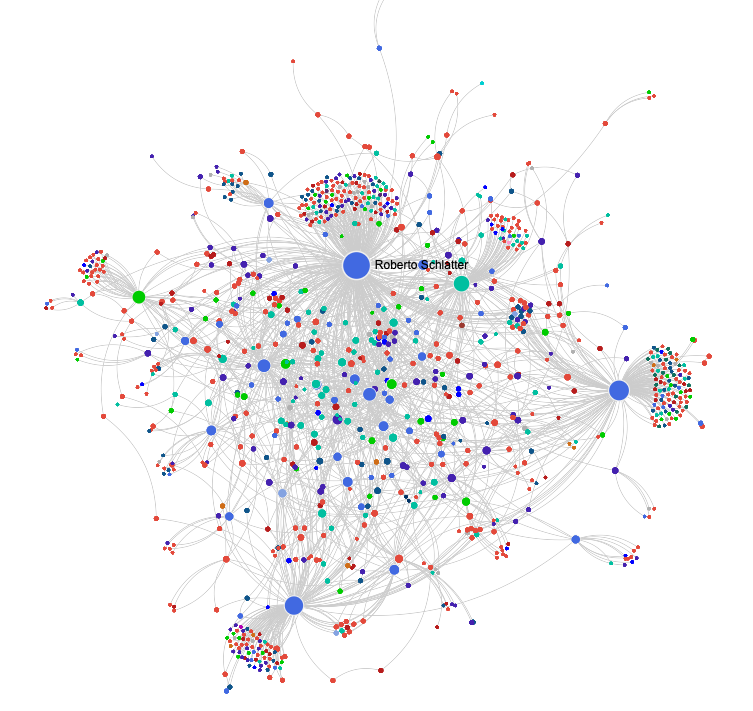
I have been transcribing every single meeting for the past 8 months. Not just the important ones. Not 50 percent. All of them.
Each transcription is automatically enriched with metadata, summarized, and fed into a vector database with an attached knowledge graph. My AI platform is connected to this graph.
Meetings are just the starting point – a particularly effective entry point because most implicit knowledge emerges in conversations. However, the same approach can be applied to virtually any knowledge source: contracts and proposals, internal documentation and wikis, email correspondence, support tickets, project reports, or regulatory documents such as SOPs and audit protocols. Wherever knowledge is fragmented across silos today, a knowledge graph can reveal connections that would otherwise be lost.
The Result: Answers in Seconds
I ask a question and get answers drawn from 8 months of conversations. Precise. With context and nuance. Without hallucinations.
| Time | Agenda Item |
|---|---|
| 08:00 | Welcome & Opening |
| Morning | Fundamentals & Case Studies – Machine Learning, Deep Learning, Generative AI, Prompt Engineering + real-world case studies |
| 12:00–13:00 | Lunch Break |
| Afternoon | Interactive Workshop Stations (max. 3–4 participants per station) |
| Afterwards | Networking |
- Training data storage location – Where is the data physically stored? Requirement: Swiss data center.
- Usage rights for fine-tuning – Who owns the trained models and weights?
- Data portability upon contract termination – How are data and models fully transferred in an exit scenario?
| Task | Status |
|---|---|
| Final slide deck | Done |
| Attendee list incl. dietary restrictions | Done |
| Budget approval for catering | Open |
| Floor plan with AV setup | Open |
Answers in seconds. Based on real knowledge. Not guesswork.
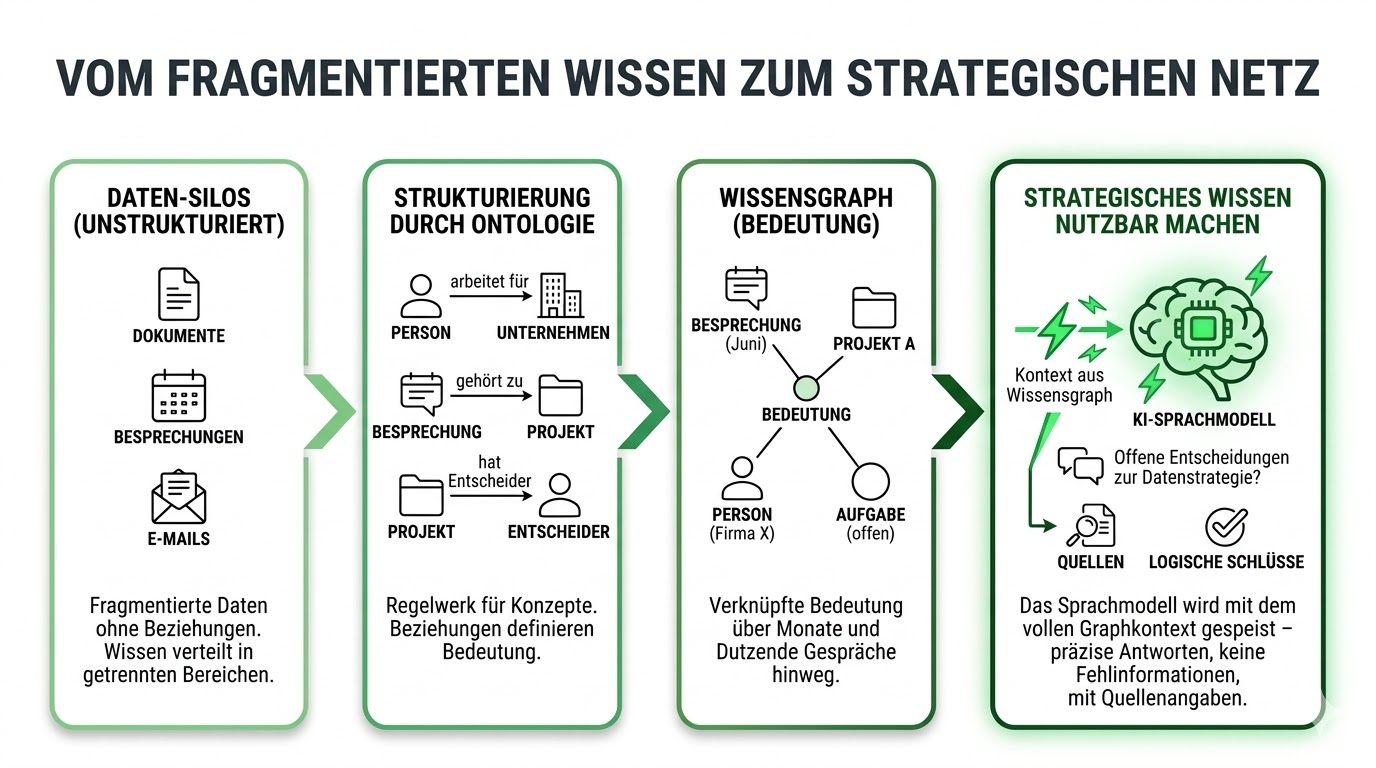
What Is a Knowledge Graph – and Why Does It Matter?
The core of this system is a knowledge graph. Not a buzzword – a data structure.
Nodes
Real-world entities: people, companies, topics, decisions, projects.
Edges
Relationships between entities: "works at", "decided", "contradicts".
Ontology
A set of rules that defines how these entities relate to each other and which relationship types are valid.
The difference from a conventional database: A knowledge graph does not just understand that two things are connected. It understands how and why. This makes it the ideal foundation for AI systems that do not merely search, but reason.
The Problem: Mountains of Unstructured Knowledge
Most organizations sit on mountains of unstructured knowledge. Meetings, emails, documents, Slack messages. Everything is there. Nothing is connected. No system that creates meaning.
| Conventional Approach | Knowledge Graph Approach |
|---|---|
| Data in silos (email, docs, chat) | All sources linked in a single graph |
| Keyword-based search | Semantic queries based on meaning |
| Context is lost | Relationships are preserved |
| AI hallucinates when data is missing | AI reasons from real knowledge |
| Information becomes outdated unnoticed | Temporal dimension is built in |
Raw model intelligence will not solve this. GPT-5, Opus 4, or Gemini 3 will not solve it either. Because the model is not the differentiator – your data and how it is connected are.
What Makes the Difference
What truly moves organizations forward are not bigger models. It comes down to three things:
Structure
Data needs a schema, an order. Without structure, everything remains fragmented – no matter how intelligent the model is.
Context
Who said what, and when? In what context? Context turns data into information and information into knowledge.
Relationships
The connections between pieces of information are often more valuable than the information itself. Relationships enable reasoning.
In a world where intelligence is becoming a commodity, meaning is the scarcest resource. Those who structure it, win.
Closing the Loop: From Graph to Language Model
However, that is only half the journey. Transcription, enrichment, and storage in the knowledge graph form the foundation – but to close the loop, this structured knowledge must be made accessible to the language model of choice. As an official partner of Langdock, we connect GDPR-compliant, EU-hosted models via MV-insights directly to the knowledge graph. This closes the circle: employees can effectively and precisely query their corporate knowledge – and receive concrete, accurate answers without hallucinations.
The Technical Architecture Behind It
For the implementation, I use a privacy-compliant infrastructure that runs entirely on Swiss and European servers:
- Transcription & Summarization: Automated real-time transcription and summarization of meetings using the GDPR-compliant tool Sally.io
- Metadata Enrichment & Automation: Workflow automation with n8n
- Vector Database: Semantic search across all transcribed content
- Knowledge Graph: Linking all entities with typed relationships
- AI Platform: GDPR-compliant language model with direct access to graph context via Langdock
The entire setup is compliant with the Swiss Data Protection Act (DSG) and can also be operated on-premise – a decisive factor for regulated industries.
Curious what this looks like in practice?
Find out how a knowledge graph system can be implemented in a privacy-compliant way for your organization.